
This guide will walk you through the steps to set up a highly available PostgreSQL release 10 cluster using Patroni and HAProxy on Ubuntu 20.04. These steps can also be applied if you are running an earlier release of Ubuntu 16.04 or 18.04.
We will use following software components to set up PostgreSQL highly available, fault-tolerant cluster:
- Patroni is a cluster manager used to customize and automate deployment and maintenance of PostgreSQL HA (High Availability) clusters.
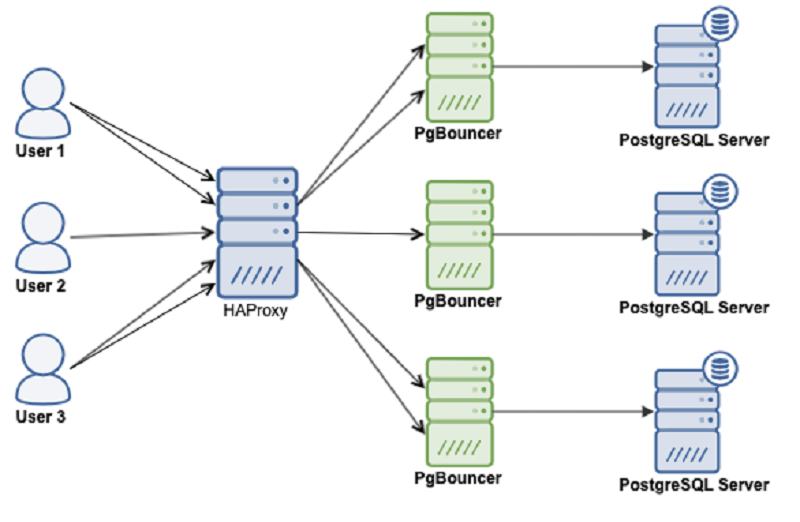
- PgBouncer is an open-source, lightweight, single-binary connection pooler for PostgreSQL. PgBouncer maintains a pool of connections for each unique user, database pair. It’s typically configured to hand out one of these connections to a new incoming client connection, and return it back in to the pool when the client disconnects.
- etcd is a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines. We will use etcd to store the state of the PostgreSQL cluster.
- HAProxy is a free and open source software that provides a high availability load balancer and reverse proxy for TCP and HTTP-based applications that spreads requests across multiple servers.
- Keepalived implements a set of health checkers to dynamically and adaptively maintain and manage load balanced server pools according to their health. When designing load balanced topologies, it is important to account for the availability of the load balancer itself as well as the real servers behind it.
The main purpose of this guide is to make PostgreSQL highly available, and to avoid any single point of failure.
Prerequisites
To follow this tutorial along, you will need a minimum of 3 (physical or virtual) machines installed with Ubuntu 20.04.
Set correct timezone on each node:
HOSTNAME IP ADDRESS PACKAGES TO BE INSTALLEDpatroni1 192.168.10.1 PostgreSQL, PgBouncer, Patroni, etcd, haproxy, keepalived patroni2 192.168.10.2 PostgreSQL, PgBouncer, Patroni, etcd, haproxy, keepalived patroni3 192.168.10.3 PostgreSQL, PgBouncer, Patroni, etcd, haproxy, keepalived
sudo timedatectl set-timezone Asia/Karachi
Set hostname on each node like below:
sudo hostnamectl set-hostname patroni1Edit /etc/hosts file:
sudo nano /etc/hosts192.168.10.1 patroni1Do not forget to replace highlighted text with yours. Save and close the editor when you are finished.
192.168.10.2 patroni2
192.168.10.3 patroni3
Make sure you repeat the same on each node before proceeding to next.
If you have all the prerequisites in place, you may proceed with the following steps to set up your PostgreSQL HA cluster.
Configure UFW Firewall (Optional)
If
ufw firewall is active on your Ubuntu, then you have to configure it
properly. The ports required for operating PostgreSQL HA cluster using (patroni, pgbouncer, etcd, haproxy, keepalived) are the following:
- 5432 PostgreSQL standard port.
- 6432 PgBouncer standard port.
- 8008 patroni rest api port required by HAProxy to check the nodes status.
- 2379 etcd client port required by any client including patroni to communicate with etcd.
- 2380 etcd peer urls port required by the etcd members communication
- 5000 HAProxy frontend listening port, establishing connection to backend database servers via pgbouncer port 6432
- 5001 HAProxy frontend listening port, establishing connection to backend replica database servers via pgbouncer port 6432
- 7000 HAProxy stats dashboard
You can allow required ports from ufw using the following command:
sudo ufw allow 5432/tcpsudo ufw allow 6432/tcpsudo ufw allow 8008/tcp
sudo ufw allow 2379/tcp
sudo ufw allow 2380/tcp
sudo ufw allow http
sudo ufw allow 5000/tcpsudo ufw allow 5001/tcpsudo ufw allow 7000/tcp
sudo ufw allow from 224.0.0.18 comment "keepalived"
sudo ufw allow to 224.0.0.18 comment "keepalived"
sudo ufw reload
Add PostgreSQL APT Repository
Type below command to add PostgreSQL official repository on your Ubuntu:
sudo apt -y install wget ca-certificates
sudo wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ $(lsb_release -cs)-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
sudo apt update
Install PostgreSQL
For this guide, we will install PostgreSQL release 10 like below:
sudo apt -y install postgresql-10
sudo systemctl stop postgresql
sudo systemctl disable postgresql
sudo ln -s /usr/lib/postgresql/10/bin/* /usr/sbin/
sudo su postgres
rm -rf /var/lib/postgresql/10/main/*
exit
Make sure you repeat the same on each node before proceeding to next.
Install etcd
You can install etcd using the following command:
sudo apt -y install etcd
sudo systemctl stop etcd
sudo systemctl disable etcd
sudo rm -rf /var/lib/etcd/default
Make sure you repeat the same on each node before proceeding to next.
Configure etcd
Edit /etc/default/etcd configuration file on your first node (patroni1) in our case, to make the required changes:
sudo mv /etc/default/etcd /etc/default/etcd-orig
sudo nano /etc/default/etcd
Add following configuration:
ETCD_NAME=patroni1
ETCD_DATA_DIR="/var/lib/etcd/patroni1"
ETCD_LISTEN_PEER_URLS="http://192.168.10.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.10.1:2380"
ETCD_INITIAL_CLUSTER="patroni1=http://192.168.10.1:2380,patroni2=http://192.168.10.2:2380,patroni3=http://192.168.10.3:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_ENABLE_V2="true"
Save and close the editor when you are finished.
Edit /etc/default/etcd configuration file on your second node (patroni2) in our case, to make the required changes:
sudo mv /etc/default/etcd /etc/default/etcd-orig
sudo nano /etc/default/etcd
Add following configuration:
ETCD_NAME=patroni2ETCD_DATA_DIR="/var/lib/etcd/patroni2"ETCD_LISTEN_PEER_URLS="http://192.168.10.2:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.10.2:2380"
ETCD_INITIAL_CLUSTER="patroni1=http://192.168.10.1:2380,patroni2=http://192.168.10.2:2380,patroni3=http://192.168.10.3:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379"ETCD_ENABLE_V2="true"
Save and close the editor when you are finished.
Edit /etc/default/etcd configuration file on your third node (patroni3) in our case, to make the required changes:
sudo mv /etc/default/etcd /etc/default/etcd-orig
sudo nano /etc/default/etcd
Add following configuration:
ETCD_NAME=patroni3ETCD_DATA_DIR="/var/lib/etcd/patroni3"ETCD_LISTEN_PEER_URLS="http://192.168.10.3:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.10.3:2380"
ETCD_INITIAL_CLUSTER="patroni1=http://192.168.10.1:2380,patroni2=http://192.168.10.2:2380,patroni3=http://192.168.10.3:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379"ETCD_ENABLE_V2="true"
Save and close the editor when you are finished.
Edit .profile on each node, and set environment variables like below:
cd ~
nano .profile
export PGDATA="/var/lib/postgresql/10/data"
export ETCDCTL_API="3"
export PATRONI_ETCD_URL="http://127.0.0.1:2379"
export PATRONI_SCOPE="pg_cluster"
patroni1=192.168.10.1
patroni2=192.168.10.2
patroni3=192.168.10.3
ENDPOINTS=$patroni1:2379,$patroni2:2379,$patroni3:2379
Make sure you repeat the same on each node before proceeding to next.
Type below command simultaneously on each node (patroni1, patroni2, patroni3) to start etcd cluster:
sudo systemctl start etcd
sudo systemctl status etcdCheck etcd cluster from any of your nodes:
source ~/.profile
etcdctl endpoint status --write-out=table --endpoints=$ENDPOINTS
You will see the output similar to like as shown in image below:

Install Patroni
Type below command to install patroni on your first node (patroni1) in our case:
sudo apt -y install python3 python3-pip python3-dev libpq-dev
sudo pip3 install launchpadlib
sudo pip3 install --upgrade setuptools
sudo pip3 install psycopg2
sudo pip3 install python-etcd
sudo apt -y install patroni
sudo systemctl stop patroni
sudo systemctl disable patroni
Make sure you repeat the same on each node before proceeding to next.
Configure Patroni
Create a configuration file for Patroni on your first node (patroni1) in our case, like below:
sudo nano /etc/patroni/config.yml
scope: pg_cluster
namespace: /service/
name: patroni1
restapi:
listen: 192.168.10.1:8008
connect_address: 192.168.10.1:8008
etcd:
hosts: 192.168.10.1:2379,192.168.10.2:2379,192.168.10.3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host replication replicator 192.168.10.1/0 md5
- host replication replicator 192.168.10.2/0 md5
- host replication replicator 192.168.10.3/0 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: 192.168.10.1:5432
connect_address: 192.168.10.1:5432
data_dir: /var/lib/postgresql/10/main
bin_dir: /usr/lib/postgresql/10/bin
pgpass: /tmp/pgpass
authentication:
replication:
username: replicator
password: replicator
superuser:
username: postgres
password: postgres
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
Next, create config.yml file on your second node (patroni2) in our case, and add the following configuration parameters:
scope: pg_cluster
namespace: /service/
name: patroni2
restapi:
listen: 192.168.10.2:8008
connect_address: 192.168.10.2:8008
etcd:
hosts: 192.168.10.1:2379,192.168.10.2:2379,192.168.10.3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host replication replicator 192.168.10.1/0 md5
- host replication replicator 192.168.10.2/0 md5
- host replication replicator 192.168.10.3/0 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: 192.168.10.2:5432
connect_address: 192.168.10.2:5432
data_dir: /var/lib/postgresql/10/main
bin_dir: /usr/lib/postgresql/10/bin
pgpass: /tmp/pgpass
authentication:
replication:
username: replicator
password: replicator
superuser:
username: postgres
password: postgres
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
Next, edit config.yml file on your third node (patroni3) in our case, and add the following configuration parameters:
scope: pg_cluster
namespace: /service/
name: patroni3
restapi:
listen: 192.168.10.3:8008
connect_address: 192.168.10.3:8008
etcd:
hosts: 192.168.10.1:2379,192.168.10.2:2379,192.168.10.3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host replication replicator 192.168.10.1/0 md5
- host replication replicator 192.168.10.2/0 md5
- host replication replicator 192.168.10.3/0 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: 192.168.10.3:5432
connect_address: 192.168.10.3:5432
data_dir: /var/lib/postgresql/10/main
bin_dir: /usr/lib/postgresql/10/bin
pgpass: /tmp/pgpass
authentication:
replication:
username: replicator
password: replicator
superuser:
username: postgres
password: postgres
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
Start Patroni Cluster
Type below command on your first node (patroni1) to start your patroni cluster:
sudo systemctl start patroni
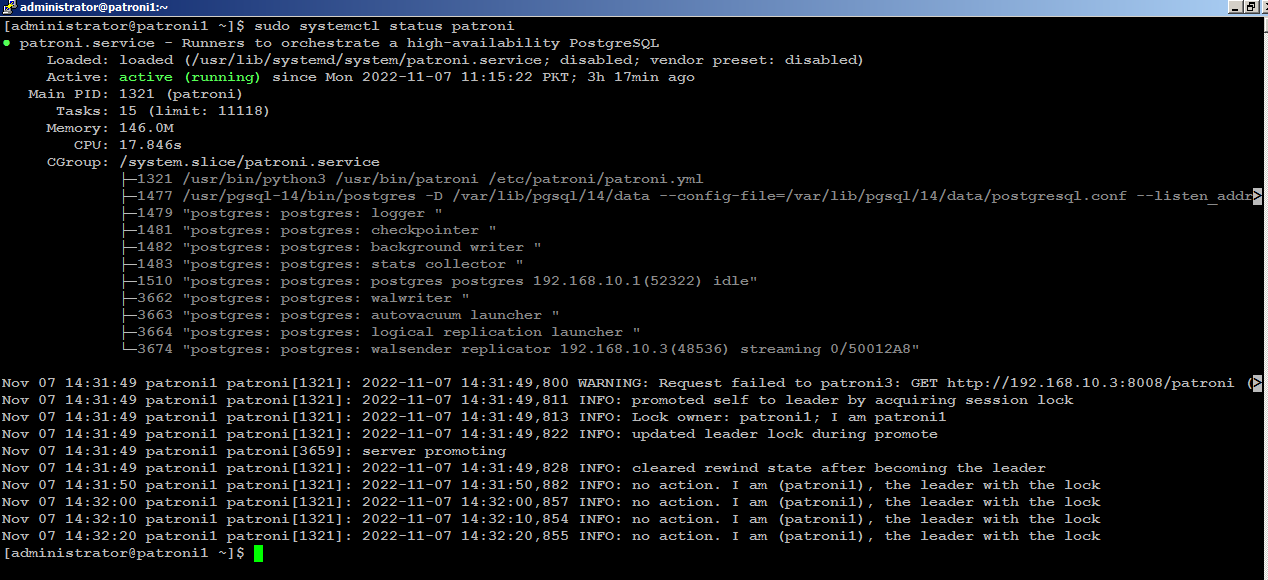
Check the patroni status with below command:
sudo systemctl status patroniIf you look carefully at the bottom of the patroni status output, you will see that the (patroni1) is acting as leader node in the cluster:
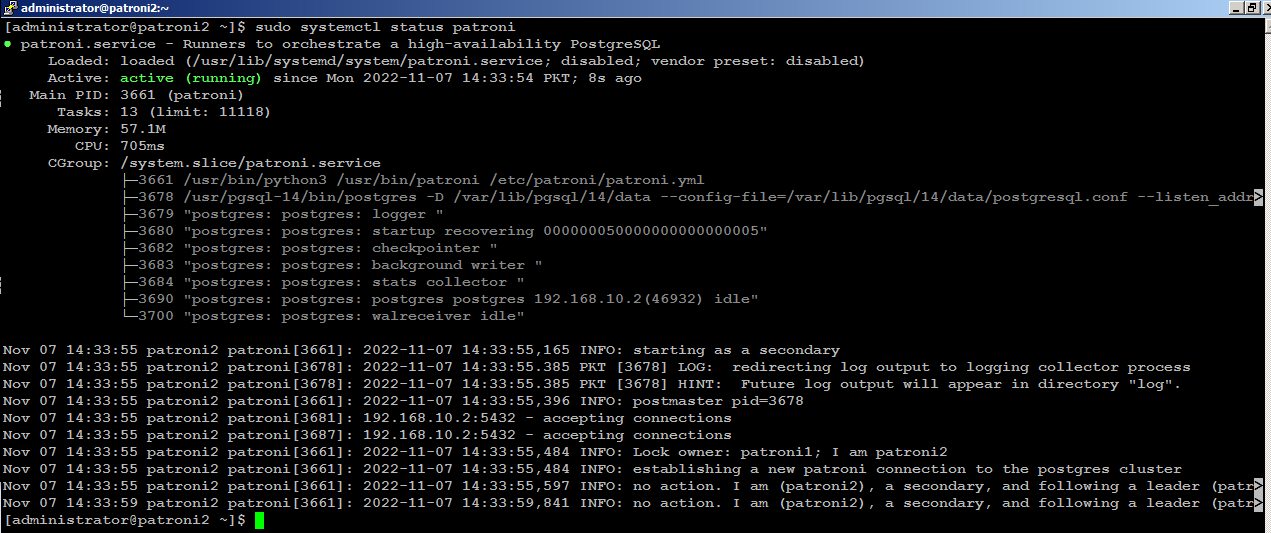
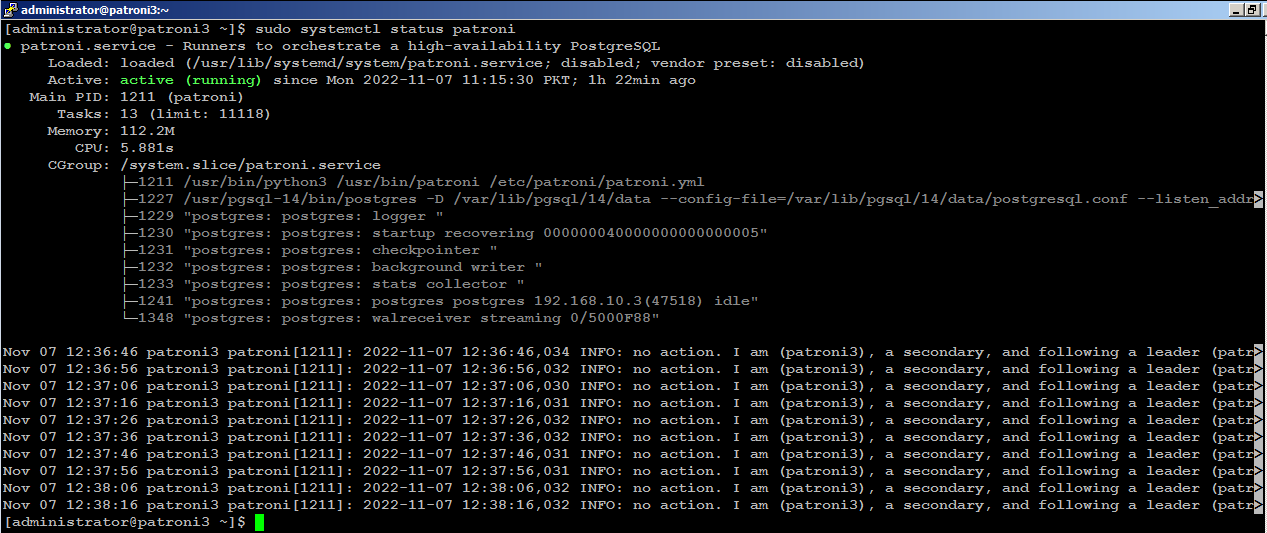
Next, start patroni on subsequent nodes, (patroni2) for example, you will see (patroni2) is acting as secondary node in the cluster:
Install PgBouncer
Type below command on your first node (patroni1) in our case to install PgBouncer:
sudo apt -y install pgbouncer
sudo systemctl stop pgbouncer
sudo systemctl disable pgbouncer
Make sure you repeat the same on each node before proceeding to next.
Configure PgBouncer
Edit /etc/pgbouncer/pgbouncer.ini file on your first node (patroni1) in our case, to make the required changes:
sudo cp -p /etc/pgbouncer/pgbouncer.ini /etc/pgbouncer/pgbouncer.ini.origAdd your database in [databases] section like below:
sudo nano /etc/pgbouncer/pgbouncer.ini
and change listen_addr=localhost to listen_addr=** = host=192.168.10.1 port=5432 dbname=postgres
listen_addr = *Since clients connect to pgbouncer, it will have to be able to authenticate them. For that, we need to create a userlist.txt file in the pgbouncer configuration directory. This userlist.txt file contains the database users and their encrypted passwords.
You can write the file by hand using the information from the pg_shadow catalog table, or you can create it automatically like below:
You can write the file by hand using the information from the pg_shadow catalog table, or you can create it automatically like below:
sudo su postgres
psql -Atq -h patroni1 -p 5432 -U postgres -d postgres -c "SELECT concat('\"', usename, '\" \"', passwd, '\"') FROM pg_shadow" >> /etc/pgbouncer/userlist.txt
exit
All the database username, and their encrypted password will be stored in /etc/pgbouncer/userlist.txt file.

This method is useful if the number of database users is small and passwords don’t change frequently. The disadvantage is whenever new user is added to PostgreSQL, the user’s username and password has to be added to userlist.txt.
Make sure you repeat the same on each node before proceeding to next.
Type below command to start PgBouncer on each node:
sudo systemctl start pgbouncerInstall Keepalived
Type below command on your first node (patroni1) in our case, to install keepalived:
sudo apt -y install keepalived
sudo systemctl stop keepalived
sudo systemctl disable keepalived
Configure Keepalived
We
will create a floating IP (192.168.10.200) to share across the nodes.
For example, if primary node (HAProxy) goes down, keepalived will
automatically configure shared IP to secondary available node in order
to keep the connectivity available and
to avoid any single point of failure.
Edit the /etc/sysctl.conf file to allow the server to bind to the virtual IP address.
sudo nano /etc/sysctl.conf
Add the net.ipv4_ip_nonlocal_bind=1
directive, which allows the server to accept connections for IP
addresses that are not bound to any of its interfaces, enabling the use
of a floating, virtual IP:
net.ipv4.ip_nonlocal_bind = 1Save and close the editor when you are finished.
net.ipv4.ip_forward = 1
Type the following command to reload settings from config file without rebooting:
sudo sysctl --system
sudo sysctl -p
Make sure you repeat the same on node before proceeding to next.
Create /etc/keepalived/keepalived.conf file on your first node (patroni1) in our case, to make the required changes:
sudo nano /etc/keepalived/keepalived.conf
Add following configuration:
vrrp_script chk_haproxy {
script "pkill -0 haproxy"
interval 5
weight -4
fall 2
rise 1
}
vrrp_script chk_lb {
script "pkill -0 keepalived"
interval 1
weight 6
fall 2
rise 1
}
vrrp_script chk_servers {
script "echo 'GET /are-you-ok' | nc 127.0.0.1 7000 | grep -q '200 OK'"
interval 2
weight 2
fall 2
rise 2
}
vrrp_instance vrrp_1 {
interface enp0s3
state MASTER
virtual_router_id 51
priority 101
virtual_ipaddress_excluded {
192.168.10.200
}
track_interface {
enp0s3 weight -2
}
track_script {
chk_haproxy
chk_lb
}
}
Do not forget to replace the highlighted text with yours. Save and close the editor when you are finished. sudo nano /etc/keepalived/keepalived.conf
Add following configuration:
vrrp_script chk_haproxy {
script "pkill -0 haproxy"
interval 5
weight -4
fall 2
rise 1
}
vrrp_script chk_lb {
script "pkill -0 keepalived"
interval 1
weight 6
fall 2
rise 1
}
vrrp_script chk_servers {
script "echo 'GET /are-you-ok' | nc 127.0.0.1 7000 | grep -q '200 OK'"
interval 2
weight 2
fall 2
rise 2
}
vrrp_instance vrrp_1 {
interface enp0s3
state BACKUP
virtual_router_id 51
priority 100
virtual_ipaddress_excluded {
192.168.10.200
}
track_interface {
enp0s3 weight -2
}
track_script {
chk_haproxy
chk_lb
}
}
Do not forget to replace the highlighted text with yours. Save and close the editor when you are finished.sudo nano /etc/keepalived/keepalived.conf
Add following configuration:
vrrp_script chk_haproxy {
script "pkill -0 haproxy"
interval 5
weight -4
fall 2
rise 1
}
vrrp_script chk_lb {
script "pkill -0 keepalived"
interval 1
weight 6
fall 2
rise 1
}
vrrp_script chk_servers {
script "echo 'GET /are-you-ok' | nc 127.0.0.1 7000 | grep -q '200 OK'"
interval 2
weight 2
fall 2
rise 2
}
vrrp_instance vrrp_1 {
interface enp0s3
state BACKUP
virtual_router_id 51
priority 99
virtual_ipaddress_excluded {
192.168.10.200
}
track_interface {
enp0s3 weight -2
}
track_script {
chk_haproxy
chk_lb
}
}
Do not forget to replace the highlighted text with yours. Save and close the editor when you are finished.sudo systemctl start keepalivedCheck on your (MASTER) node to see if your (enp0s3) network interface has configured with an additional shared IP (192.168.10.200):
ip addr show enp0s3You will see the output similar to like below:
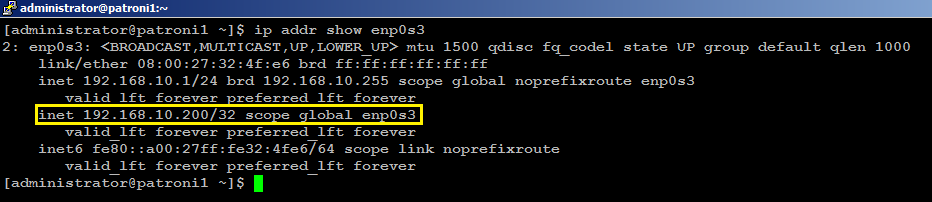
With this configuration, if haproxy goes down on your MASTER node, keepalived will automatically failover to BACKUP node, and connectivity will remain available to your clients.
Install HAProxy
With
patroni, you need a method to connect to the leader
node regardless of which of the node in the cluster is the leader.
HAProxy forwards the connection to whichever node is currently the
leader. It does this using a REST endpoint that Patroni provides.
Patroni ensures that, at any given time, only the leader node will
appear as online, forcing HAProxy to connect to the correct node. Users
or applications, (psql) for
example, will connect to haproxy, and haproxy will make sure connecting
to the leader node in the cluster.
Type below command to install haproxy on your first node (patroni1) in our case:
sudo apt -y install haproxy
sudo systemctl stop haproxy
sudo systemctl disable haproxy
Make sure you repeat the same on each node before proceeding to next.
Configure HAProxy
Edit haproxy.cfg file on your first node (patroni1) in our case, to make required changes:
sudo mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.orig
sudo nano /etc/haproxy/haproxy.cfg
Add following configuration:
global
log 127.0.0.1 local2
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
maxconn 4000
daemon
defaults
mode tcp
log global
option tcplog
retries 3
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 3000
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen primary
bind 192.168.10.200:5000
option httpchk OPTIONS /master
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server patroni1 192.168.10.1:6432 maxconn 100 check port 8008
server patroni2 192.168.10.2:6432 maxconn 100 check port 8008
server patroni3 192.168.10.3:6432 maxconn 100 check port 8008
listen standby
bind 192.168.10.200:5001
balance roundrobin
option httpchk OPTIONS /replica
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server patroni1 192.168.10.1:6432 maxconn 100 check port 8008
server patroni2 192.168.10.2:6432 maxconn 100 check port 8008
server patroni3 192.168.10.3:6432 maxconn 100 check port 8008
Make sure you replace the highlighted text with yours. Save and close the editor when you are finished.
There are two sections in haproxy configuration: one is primary, using port 5000, and other is standby, using port 5001.
All three nodes are included in both sections: that is because all the nodes are potential candidates to be either primary or secondary. Patroni provides a built-in REST API support for health check monitoring that works perfectly with HAproxy. HAProxy will send an HTTP request to port 8008 of patroni to know which role each node currently has.
All three nodes are included in both sections: that is because all the nodes are potential candidates to be either primary or secondary. Patroni provides a built-in REST API support for health check monitoring that works perfectly with HAproxy. HAProxy will send an HTTP request to port 8008 of patroni to know which role each node currently has.
The
haproxy configuration will remain same on each node so make sure you
repeat the same on your remaining nodes before proceeding to next.
Type below command to start HAProxy on each node:
sudo systemctl start haproxy
Check HAProxy status:
sudo systemctl status haproxyYou can manually test keepalived failover scenario by killing haproxy on your MASTER node with sudo systemctl stop haproxy command, and within few seconds of delay 192.168.10.200 will automatically be configured on your BACKUP node.
Test Patroni Cluster
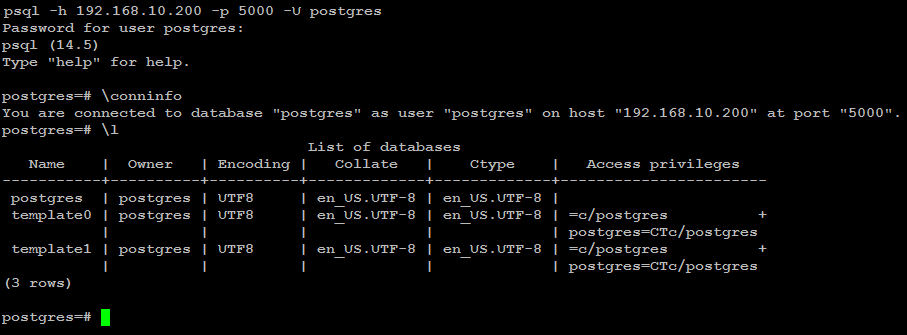
You can test your Patroni cluster by initiating a connection request from any of your applications (psql) for example to your (shared_ip:port), and see if this successfully establish connection back to the database leader node in the cluster.
psql -h 192.168.10.200 -p 5000 -U postgresAs you can see in the image below, the (psql) successfully connected to database via haproxy using shared ip:
Execute two read-request to verify HAProxy round-robin mechanism is working as expected:
psql -h 192.168.10.200 -p 5001 -U postgres -t -c "select inet_server_addr()"
Execute the same read-request second time:
psql -h 192.168.10.200 -p 5001 -U postgres -t -c "select inet_server_addr()"
You can test write-request by executing same command but using port 5000:
psql -h 192.168.10.200 -p 5000 -U postgres -t -c "select inet_server_addr()"

As you can see, in the primary section (patroni1) row is highlighted in green. This indicates that 192.168.10.1 is currently a leader node in the cluster.
In the standby section, the (patroni2, patroni3) row is highlighted as green. This indicates that both nodes are replica node in the cluster.
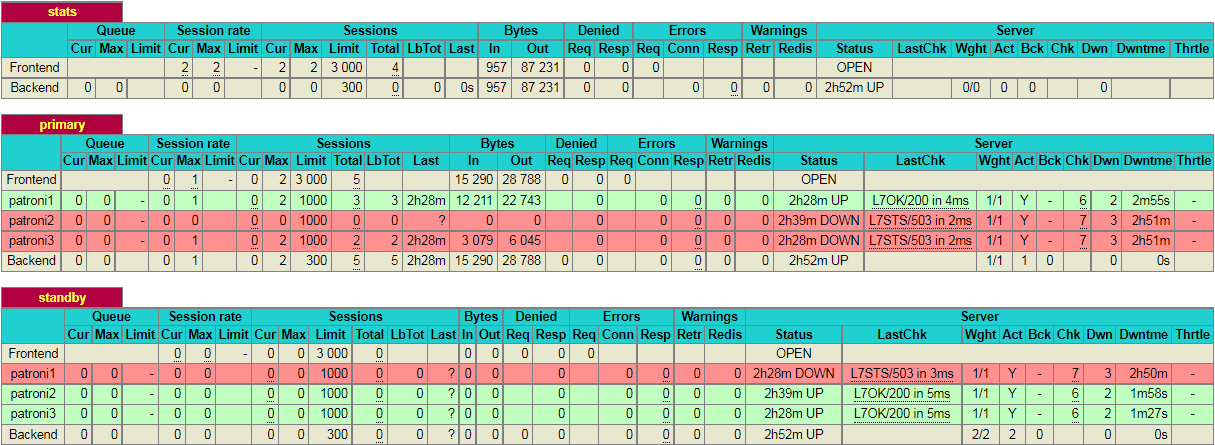
If you kill the leader node using (sudo systemctl stop patroni) or by completely shutting down the server, the dashboard will look similar to like below:
As you can see, in the primary section (patroni2) row is now highlighted in green. This indicates that 192.168.10.2 is currently a leader node in the cluster.
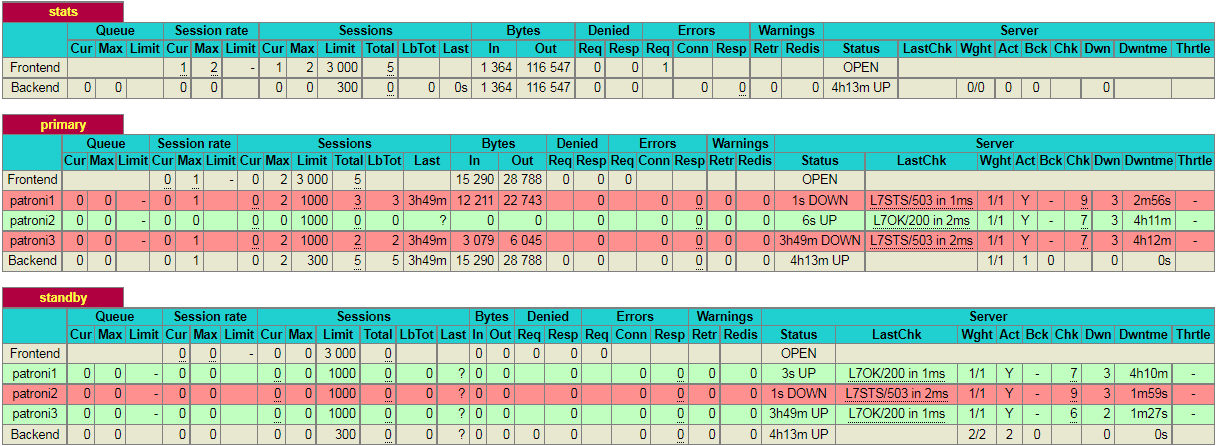
Please
note that, in this particular scenario, it just so happens that the
second node in the cluster is promoted to leader. This might not always
be the case and it is equally likely that the 3rd node may be promoted
to leader.
Test Database Replication
We will create a test database to see if it is replicated to other nodes in the cluster. For this guide, we will use (psql) to connect to database via haproxy like below:
psql -h 192.168.10.200 -p 5000 -U postgrescreate database testdb;
create user testuser with encrypted password 'mystrongpass';
grant all privileges on database testdb to testuser;
\qStop patroni on leader node (patroni1) in our case with below command:
sudo systemctl stop patronipsql -h 192.168.10.200 -p 5000 testuser -d testdb
Now bring up your first node with (sudo systemctl start patroni), and it will automatically rejoin the cluster as secondary and automatically synchronize with the leader.
Patroni Cluster Failover
With
patronictl,
you can administer, manage and troubleshoot your PostgreSQL cluster.
Type below command to list the options and commands you can use
with patronictl:
sudo patronictl --helpThis will show you the options and commands you can use with patronictl.
Options:
-c, --config-file TEXT Configuration file
-d, --dcs TEXT Use this DCS
-k, --insecure Allow connections to SSL sites without certs
--help Show this message and exit.
Commands:
configure Create configuration file
dsn Generate a dsn for the provided member, defaults to a dsn of...
edit-config Edit cluster configuration
failover Failover to a replica
flush Discard scheduled events (restarts only currently)
history Show the history of failovers/switchovers
list List the Patroni members for a given Patroni
pause Disable auto failover
query Query a Patroni PostgreSQL member
reinit Reinitialize cluster member
reload Reload cluster member configuration
remove Remove cluster from DCS
restart Restart cluster member
resume Resume auto failover
scaffold Create a structure for the cluster in DCS
show-config Show cluster configuration
switchover Switchover to a replica
version Output version of patronictl command or a running Patroni Check patroni member nodes:
patronictl -c /etc/patroni/config.yml list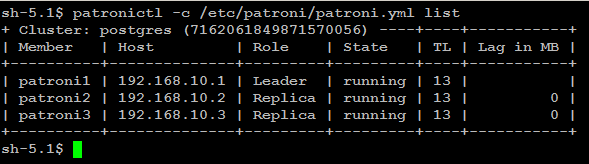
Check failover/switchover history:
patronictl -c /etc/patroni/config.yml history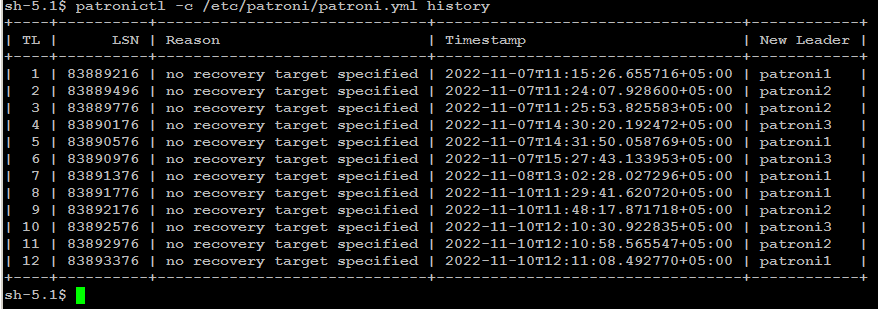
Remember: failover is executed automatically, when the Leader node is getting
unavailable for unplanned reason. If you wish to test failover across
the nodes in the cluster, you can manually initiate failover to a
replica node with below command:
patronictl -c/etc/patroni/config.ymlfailover
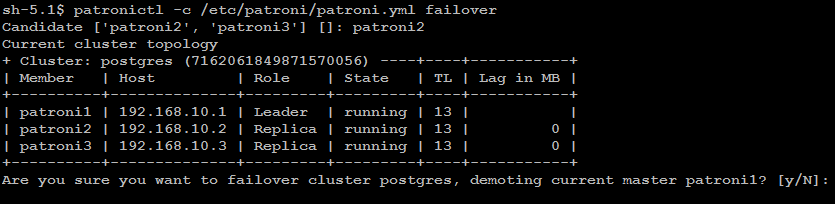
In some cases it is necessary to perform maintenance task on a single
node such as applying patches or release updates. When you manually
disable auto failover, patroni won’t change the state of the
PostgreSQL cluster.
You can disable auto failover with below command:
patronictl -c /etc/patroni/config.yml pausePatroni Cluster Switchover
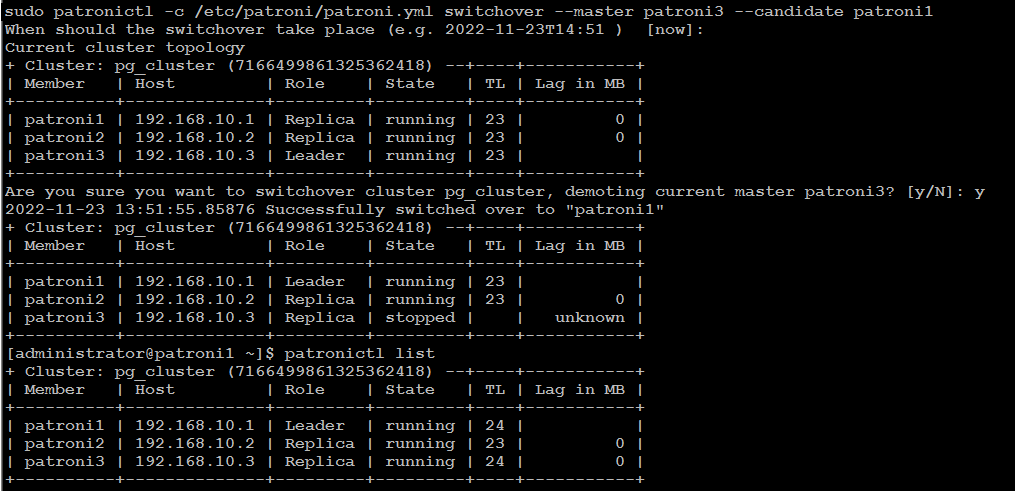
There
are two possibilities to run a switchover, either in scheduled mode or
immediately. At the given time, the switchover will take place, and you
will see in the logfile an entry of switchover activity.
patronictl -c /etc/patroni/config.yml switchover --master your_leader_node --candidate your_replica_nodeIf you go with [now] option, switchover will take place immediately.
Simulate Patroni Cluster Failure Scenarios
To simulate failure scenarios in production environment, we will execute continuous reads and writes to the database using a simple Python script as we are interested in observing the state of the cluster upon a server failure.You should have a Linux workstation with PostgreSQL client, and PostgreSQL driver for Python installed:
sudo apt -y install postgresql-client python3-psycopg2
Download HAtester.py script on your Linux workstation:
cd ~
curl -LO https://raw.githubusercontent.com/jobinau/pgscripts/main/patroni/HAtester.py
chmod +x HAtester.py
Edit HAtester.py and replace database credentials with yours:
nano HAtester.pyReplace following credentials with yours:
host = "192.168.10.200"
dbname = "postgres"
user = "postgres"
password = "your_postgres_user_password"
You need to create a target table "HATEST" in your database before executing HAtester.py script:
psql -h 192.168.10.200 -p 5000 -U postgres -c "CREATE TABLE HATEST (TM TIMESTAMP);"
psql -h 192.168.10.200 -p 5000 -U postgres -c "CREATE UNIQUE INDEX idx_hatext ON hatest (tm desc);"
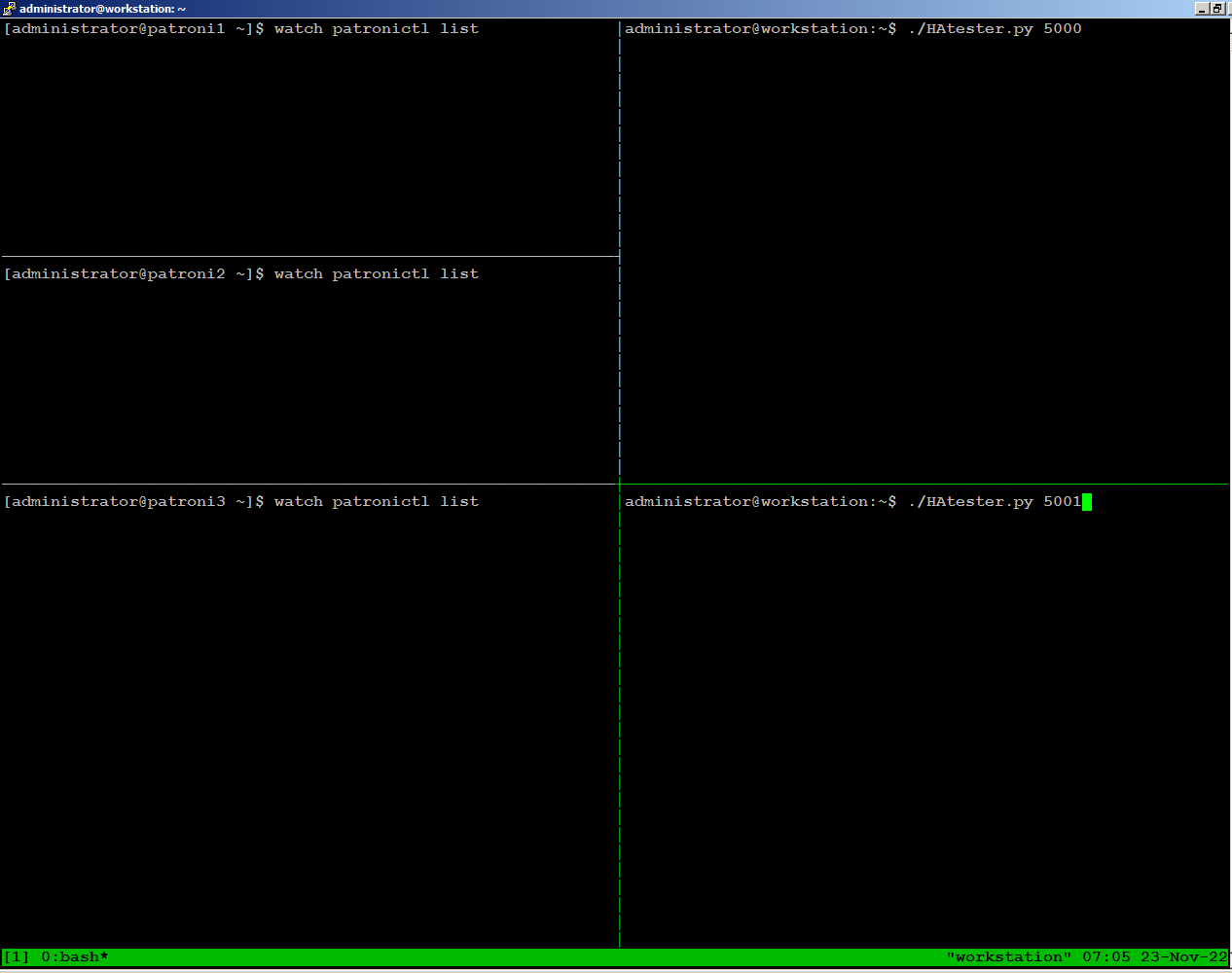
On
the left side of the screen, we have one ssh session open for each of
the 3 nodes, continuously monitoring patroni cluster state:
On the right side of the screen, we are running the HAtester.py script sending writes through port 5000, and reads through port 5001 from our workstation:
On the right side of the screen, we are running the HAtester.py script sending writes through port 5000, and reads through port 5001 from our workstation:
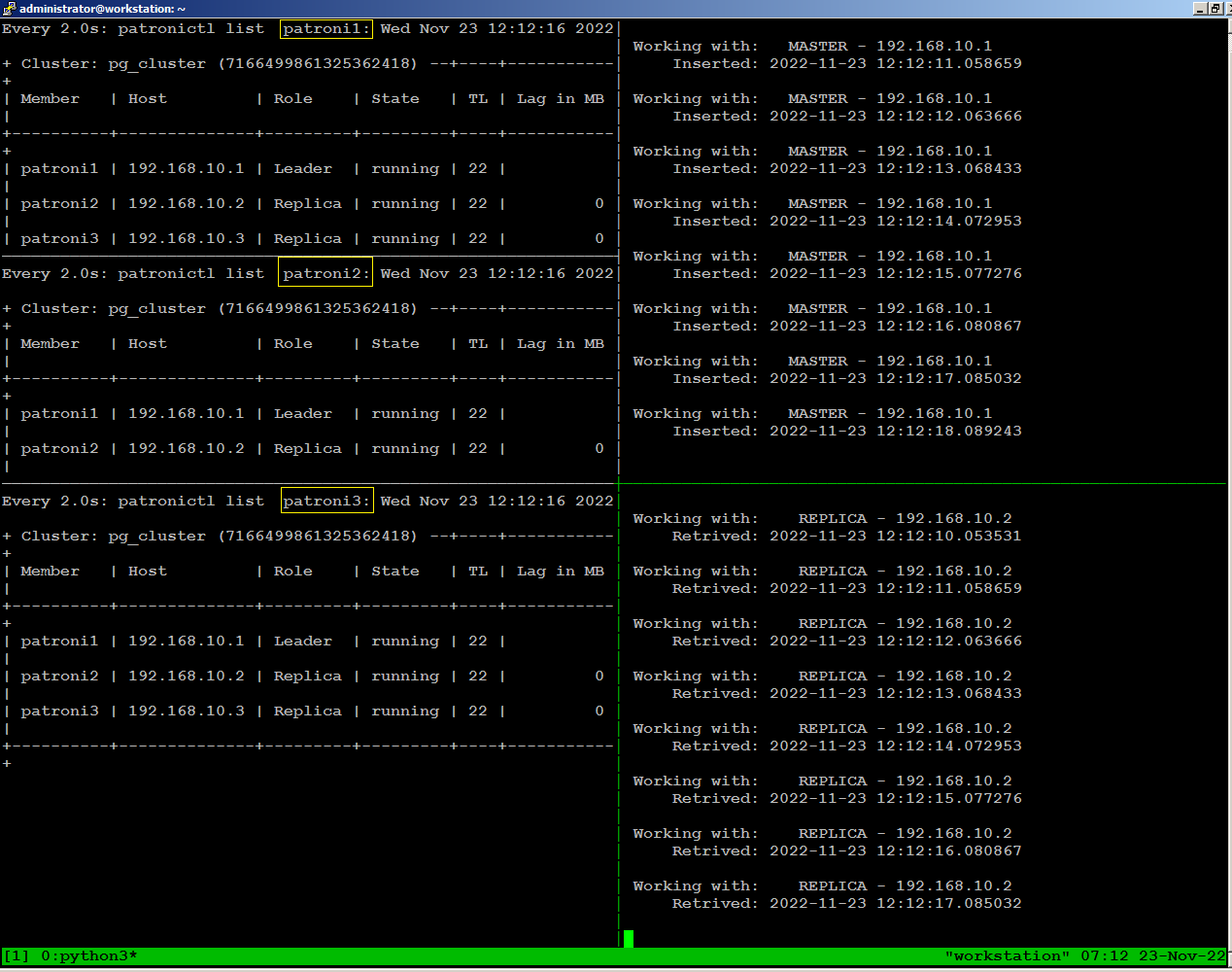
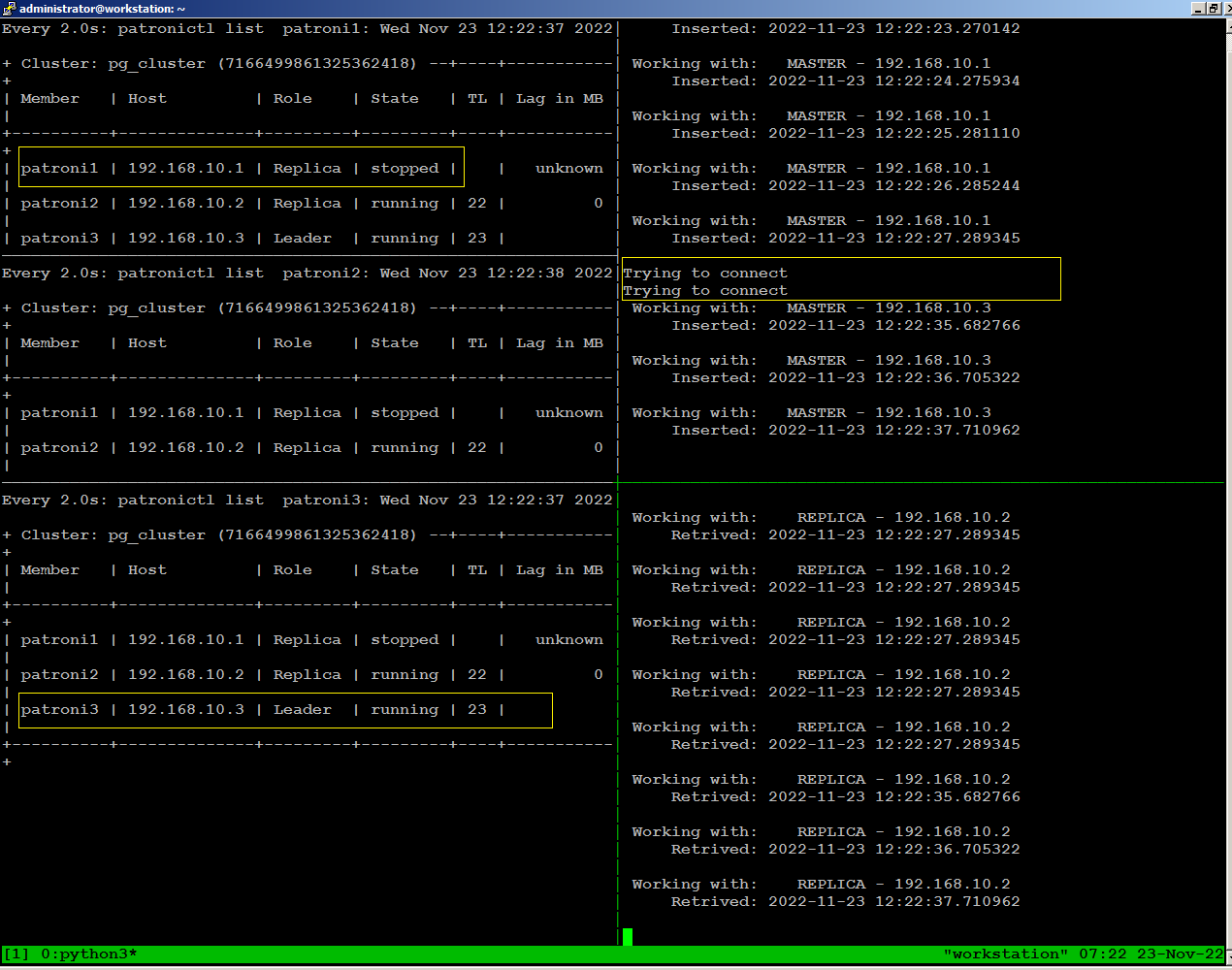
To
observe what happens with database traffic when the environment
experiences a failure, we will manually stop patroni on our leader node
using the following command:
sudo systemctl stop patroniWhen we stopped patroni on leader node, within few seconds a replica
node become leader, and continues writing to the database stopped for
few seconds, then reconnected automatically.
There is no disconnection
happens to continues reading to the database because replica node was
available throughout.
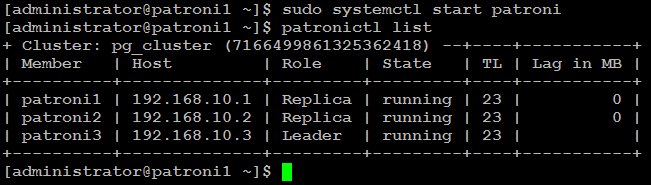
sudo systemctl start patroniThe node has automatically rejoined the cluster as replica:
Test Environment Failure Scenarios
We
leave it up to you to test and experiment with your patroni cluster to
see what happens when environment experiences a failure such as:
When simulating these tests, you should continuously monitor how the patroni cluster re-adjusts itself and how it affects read and write traffic for each failure scenario.
- Loss of network connectivity
- Power breakdown
When simulating these tests, you should continuously monitor how the patroni cluster re-adjusts itself and how it affects read and write traffic for each failure scenario.
Conclusion
I hope this guide was helpful to set up a highly available PostgreSQL release 10 cluster on Ubuntu 20.04 for your production use.
thanks same configuration i had done but replication not working in leader node new database created that was not showing in replica node...please share any suggestion
ReplyDeleteError: 'Failed to bootstrap cluster'
ReplyDeleteDec 23 09:43:23 agppgsql01 systemd[1]: Started High availability PostgreSQL Cluster.
Dec 23 09:43:24 agppgsql01 patroni[72272]: 2021-12-23 09:43:24,639 INFO: No PostgreSQL configuration items changed, nothing to reload.
Dec 23 09:43:24 agppgsql01 patroni[72272]: 2021-12-23 09:43:24,663 INFO: Lock owner: None; I am agppgsql01
Dec 23 09:43:24 agppgsql01 patroni[72272]: 2021-12-23 09:43:24,671 INFO: trying to bootstrap a new cluster
Dec 23 09:43:24 agppgsql01 patroni[72272]: 2021-12-23 09:43:24,679 ERROR: Exception during execution of long running task bootstrap
Dec 23 09:43:24 agppgsql01 patroni[72272]: Traceback (most recent call last):
Dec 23 09:43:24 agppgsql01 patroni[72272]: File "/usr/local/lib/python3.8/dist-packages/patroni/async_executor.py", line 97, in run
Dec 23 09:43:24 agppgsql01 patroni[72272]: wakeup = func(*args) if args else func()
Dec 23 09:43:24 agppgsql01 patroni[72272]: File "/usr/local/lib/python3.8/dist-packages/patroni/postgresql/bootstrap.py", line 294, in bootstrap
Dec 23 09:43:24 agppgsql01 patroni[72272]: return do_initialize(config.get(method)) and self._postgresql.config.append_pg_hba(pg_hba) \
Dec 23 09:43:24 agppgsql01 patroni[72272]: File "/usr/local/lib/python3.8/dist-packages/patroni/postgresql/bootstrap.py", line 81, in _initdb
Dec 23 09:43:24 agppgsql01 patroni[72272]: ret = self._postgresql.pg_ctl('initdb', *options)
Dec 23 09:43:24 agppgsql01 patroni[72272]: File "/usr/local/lib/python3.8/dist-packages/patroni/postgresql/__init__.py", line 199, in pg_ctl
Dec 23 09:43:24 agppgsql01 patroni[72272]: return subprocess.call(pg_ctl + ['-D', self._data_dir] + list(args), **kwargs) == 0
Dec 23 09:43:24 agppgsql01 patroni[72272]: File "/usr/lib/python3.8/subprocess.py", line 340, in call
Dec 23 09:43:24 agppgsql01 patroni[72272]: with Popen(*popenargs, **kwargs) as p:
Dec 23 09:43:24 agppgsql01 patroni[72272]: File "/usr/lib/python3.8/subprocess.py", line 858, in __init__
Dec 23 09:43:24 agppgsql01 patroni[72272]: self._execute_child(args, executable, preexec_fn, close_fds,
Dec 23 09:43:24 agppgsql01 patroni[72272]: File "/usr/lib/python3.8/subprocess.py", line 1704, in _execute_child
Dec 23 09:43:24 agppgsql01 patroni[72272]: raise child_exception_type(errno_num, err_msg, err_filename)
Dec 23 09:43:24 agppgsql01 patroni[72272]: FileNotFoundError: [Errno 2] No such file or directory: 'pg_ctl'
Did you install python 3.8? Also share your Linux distribution i.e. Ubuntu or Debian? Release?, and your postgresql version?
Delete